In this post, we’ll take the Semeion Handwritten Digits data set and cluster the handwritten digits data using the EM algorithm with a principle components step within each maximization.
First, we’ll read in the data, load the additional libraries, and create our initial data table.
library("mvtnorm")
library("data.table")
# Reading data and convert to data table
setwd("C:/Users/Josh/Documents/GitHub/joshuahancock.github.io/data_sets/")
data <- fread("C:/Users/Josh/Documents/GitHub/joshuahancock.github.io/data_sets/semeion.csv", header = FALSE)Each row of the data represents one handwritten digit, which were digitally scanned and stretched into a 16x16 pixel box. Each of these 256 pixels, originally in grey scale, was thresholded into a binary value that indicates ‘black’ or ‘white’ for that pixel. There are 10 additional columns (also binary), which indicate group membership. We’ll need to separate those labels into their own data table.
x <- data[, 1:256]
labels <-apply(data[, 257:266], 1, function(xx){return(which(xx == "1") -1)})Before we start clustering, we need to take care of a few global variables and run our initial clustering algorithm.
# k is the number of clusters
k <- 10
# n is the number of observations
n <- nrow(x)
# d is the number of diwmensions
d <- ncol(x)
# q represents the number of principal components and will need to be manually changed
q <- 6
# x.clusters are the clusters using k means and 100 random starts
x.clusters <- kmeans(x, k, nstart = 100)Now that we have preliminary clusters, we’ll initialize our \(\gamma\) matrix, which will hold the cluster membership probabilities for each observation. We then use \(\gamma\) to calculate \(\Pi_k\), the proportion of observations assigned to cluster \(k\), and \(\mu_k\), the mean of the observations within each cluster \(k\).
# n by k matrix, initialized with zeros
gamma <- matrix(0, n, k)
# indicate the inital custer membership with a binary label
for(i in 1:n) {gamma[i, x.clusters$cluster[i]] = 1}
# the number of members in each cluster
N <- colSums(gamma)
# the percentage of the data set in cluster k
pi.hat <- N/n
# the mean for each pixel in each cluster
# note: a matrix is required for the t() function
mu.hat <- (t(gamma) %*% data.matrix(x))/ NBefore beginning the EM algorithm, we must initialize a covariance matrix for each pixel of each cluster. To do this, we’ll write a function to calculate the covariance for each cluster and store the result in a list of length \(k\).
sigma.k <- function(GAMMA, X, MU, X.CLUSTERS, q){
# initialize empty list to hold sigma matricies
sigma.list <- list()
# normailze columns
g.norm <- t(t(GAMMA)/N)
# iterate over each cluster
for(i in 1:k){
# for each observation in the data set, subtract the mu
x.mu <- t(apply(X, 1, function(xx) xx-MU[i, ]))
# create convariance matrix
g.x.mu <- t(g.norm[, i] * x.mu) %*% x.mu
# eigen decomposition
x.decomp <- eigen(g.x.mu)
# principal components step
if(q > 0){
sig.hat <- sum(x.decomp$values[as.integer(q + 1):as.integer(d)]) / (d - q)
decomp.vec <- x.decomp$vectors[, 1:q]
lambda <- x.decomp$values[1:q]
W <- decomp.vec %*% (diag(q) * sqrt(lambda - sig.hat)) %*% t(decomp.vec)
sigma.list[[i]] <- W %*% t(W) + sig.hat * diag(d)
}
else {
sigma.list[[i]] <- diag(d) * sum(x.decomp$values) / d
}
}
return(sigma.list)
}Now that we’ve defined our function, we can initialize our \(\Sigma\) element:
sigma.hat <- sigma.k(gamma, x, mu.hat, x.clusters, q)Now that we have our basis functions and structure initialized, we can begin with the E and M steps of the process. In order to do that, we need to define a few more functions. First, we’ll update our \(\gamma\) matrix with the following function:
update.gamma <- function(PI, SIGMA , X, MU){
# a temp matrix to store gamma values
p.mu.sig <- matrix(nrow = n, ncol = k)
# iterate over clusters
for(i in 1:k){
# weight raw probabilities by pi
p.mu.sig[, i] <- PI[i] * dmvnorm(X, MU[i, ], SIGMA[[i]])
}
weights <- rowSums(p.mu.sig)
# returns normalized rows
return(p.mu.sig / weights)
}Next, we need a function to calculate the log likelihood:
LL <- function(PI, SIGMA, X, MU){
# keeps a running track of the sum
iter.sum <- c(rep(0, n))
for(i in 1:k){
iter.sum <- iter.sum + PI[i] * dmvnorm(X, MU[i, ], SIGMA[[i]])
}
return(sum(log(iter.sum)))
}Finally, we need a function to calculate the AIC so that we’ll be able to pick the proper number of principal components to use with our algorithm.
AIC <- function(LL, q){
return(-2 * LL + 2 * (d * q + 1 - q* (q - 1) / 2))
}Now, we’re ready to begin our algorithm. The first step, or \(E\) step, updates the \(\gamma\) matrix. The second, or \(M\), step calculates the new \(\mu_k\), \(\pi_k\), and \(\Sigma_k\) based on the updated \(\gamma\) matrix. At the end of each iteration the log likelihood is calculated and after a predetermined number of iterations, the process should converge. Here, we will choose 50 iterations, which we will then examine graphically.
LL.list <- c()
AIC.list <- c()
iters <- 0
while(iters < 51){
gamma <- update.gamma(pi.hat, sigma.hat, x , mu.hat)
N <- colSums(gamma)
pi.hat <- N / n
mu.hat <- (t(gamma) %*% as.matrix(x)) / N
sigma.hat <- sigma.k(gamma, x, mu.hat, x, q)
log.likelihood <- LL(pi.hat, sigma.hat, x, mu.hat)
LL.list <- c(LL.list, log.likelihood)
iters <- iters + 1
}
AIC.q <- AIC(tail(LL.list, 1), q)
AIC.list <- c(AIC.list, AIC.q)
if(q == 0){
ll.plot <- as.matrix(LL.list)
} else{
print(iters)
ll.plot <- cbind(ll.plot, LL.list)
}
AIC.table <- rbind(AIC.table, cbind(q, AIC.q)Some simple code to plot the log likelihood for each \(q\):
# a vector of q values
q.list <- c(0, 2, 4, 6)
par(mfrow=c(2,2))
# plot each column of the object holding our likelihood values
for(i in 1:4){
plot(ll.plot[, i], ylab = "Log Likelihood", xlab = "Iteration",
main=paste("q", q.list[i], sep= " = "))}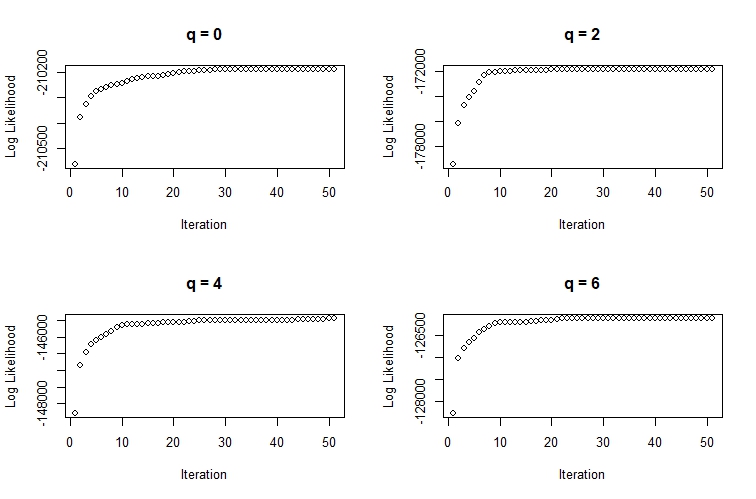
Fig 1: convergance of the EM algorithm
As we can see from the plots, the algorithm needed far fewer than 50 iterations to converge. We can also see the dramatic change in log likelihood values and \(q\) increases. As previously mentioned, we’re using the value of \(q\) which minimizes AIC:
| q | AIC |
|---|---|
| 6 | 255256.93 |
| 4 | 291812.73 |
| 2 | 346328.17 |
| 0 | 420376.53 |
We can see that \(q = 6\) minimizes the AIC, so that is the number of principal components we’ll use for our model, which we’ll now assess for accuracy. First, we’ll create a panel plot comparing the mean of each cluster to a five random draws from the distribution.
par(mai = c(0.05, 0.05, 0.05, 0.05), mfrow = c(10, 6))
for(i in 1:k){
image(t(matrix(mu.hat[i, ], byrow = TRUE, 16, 16)[16:1, ]), col = topo.colors(255, alpha = 0.75), axes = FALSE)
box()
for(j in 1:5){
randomPick <- rmvnorm(1, mu.hat[i, ], sigma.hat[[i]])
image(t(matrix(randomPick, byrow=TRUE, 16, 16)[16:1, ]), col = topo.colors(255, alpha = 0.75), axes = FALSE)
}
}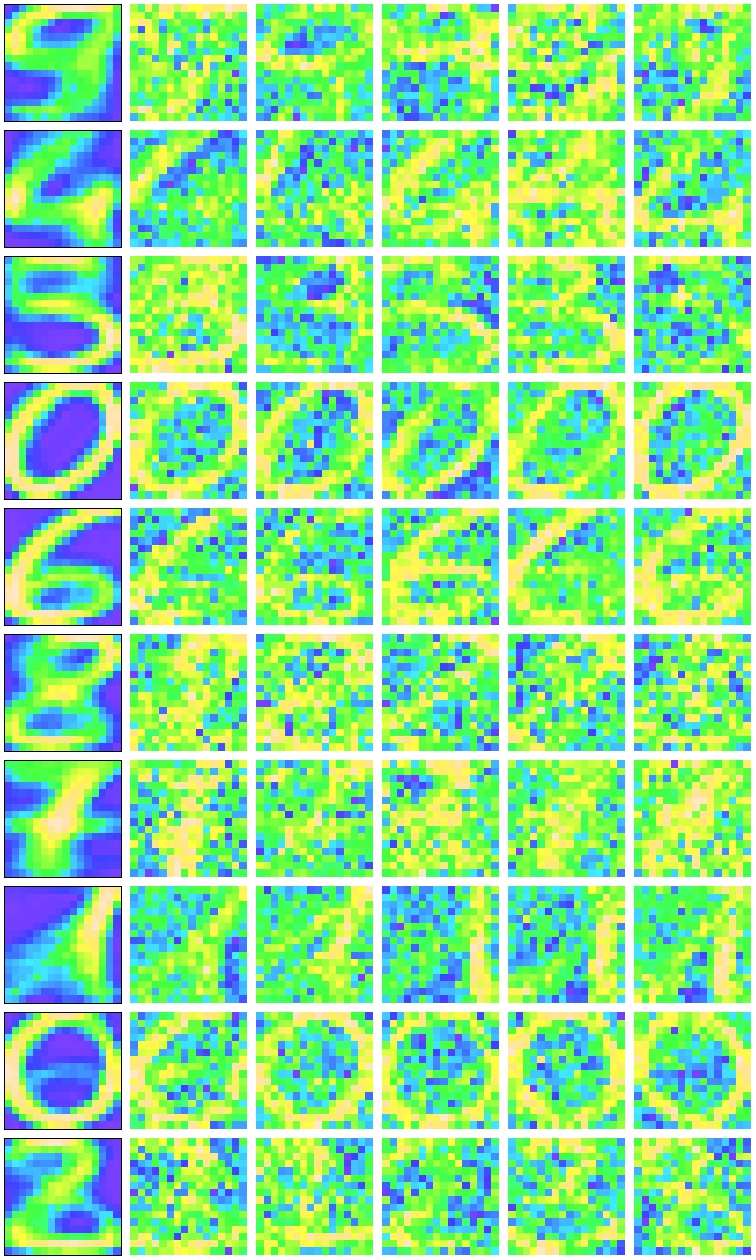
Fig 2: cluster means versus random draws
A visual inspection reveals quite a bit of about the clusters. The cluster means are much more discernible than random draws from the distribution. Several are the numbers are quite distinguishable, while others are less defined, especially in pixels that intersect with similar numbers. Zero appears twice, and numbers two and three have gotten mixed in with other digits.
The next step will be to examine the classification and misclassification rates of our model. We must first define one of these rates, as the other is simply \((1 - rate)\). Using the ground truth labels, we will define the misclassification rate as the proportion of each digit not assigned to the same cluster that the majority of that digit is assigned to. The following code will allow us to calculate the misclassification rates for each digit.
get.mode <- function(x) {
x.values <- unique(x)
totals <- tabulate(match(x, x.values))
return(c(x.values[which.max(totals)], max(totals)))
}
which.digit <- c()
for(i in 1:n){
which.digit <- c(which.digit, which.max(gamma[i, ]) )
}
digit.mapping <- matrix(0, 10, 2)
for(ii in 1:k){
indices <- which(which.digit == ii - 1)
digit.mapping[ii, ] <- get.mode(which.digit[indices]) }
ground.truth <- tabulate(match(which.digit, unique(which.digit)))
truth.prop <- digit.mapping[, 2] / ground.truth
mis.truth <- 1 - truth.prop
mis.class <- 1 - sum(digit.mapping[, 2]) / n| Digit | Cluster | Quantity | Total | MCR |
|---|---|---|---|---|
| 0 | 1 | 87 | 161 | 0.46 |
| 1 | 7 | 99 | 162 | 0.39 |
| 2 | 3 | 105 | 159 | 0.34 |
| 3 | 6 | 105 | 159 | 0.34 |
| 4 | 8 | 138 | 161 | 0.14 |
| 5 | 10 | 76 | 159 | 0.52 |
| 6 | 4 | 116 | 161 | 0.28 |
| 7 | 2 | 134 | 159 | 0.15 |
| 8 | 5 | 118 | 155 | 0.24 |
| 9 | 10 | 78 | 158 | 0.51 |
This MCR table helps shed some light on inferences we made from the previous plots. Cluster 9, which most closely resembles a zero, was not the most common cluster for any digit. Cluster 10 was the most common cluster for both five and nine. The clusters with the lower misclassification rate tend to be the clusters with the most clearly defined mean plots in Fig 2.
